
在数据库管理中,处理重复数据是关键任务。本文将介绍几种使用SQL查询重复数据的方法,并通过实例进行演示,帮助读者更好地理解和掌握这些技巧。
一、使用GROUP BY 和HAVING 子句
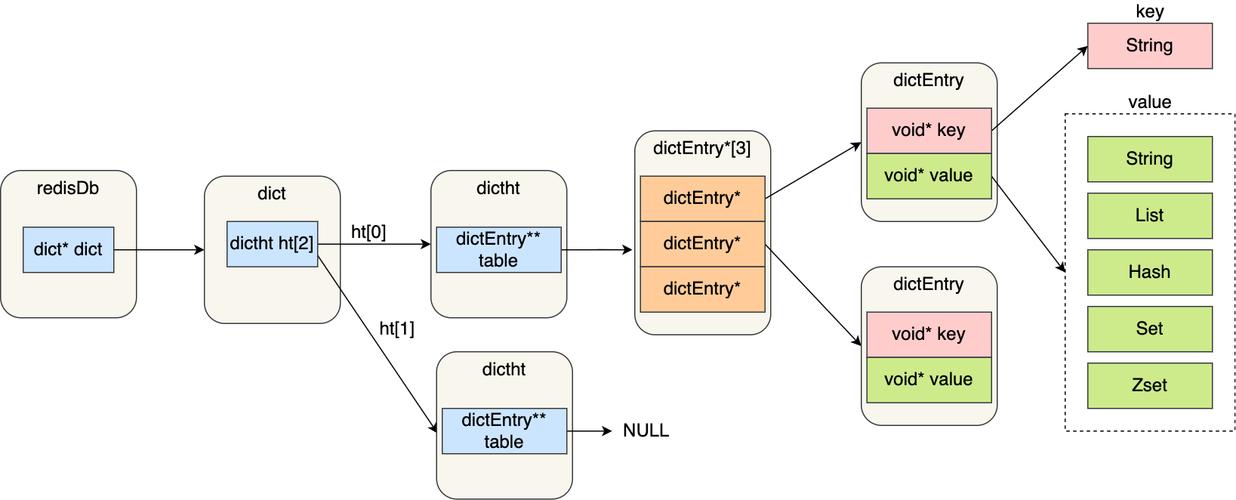
(图片来源网络,侵权删除)
1、基础用法:
通过GROUP BY 子句可以将数据按照一个或多个列进行分组。
结合HAVING 子句,可以筛选出分组后满足特定条件(如计数超过一定数量)的数据组。
2、示例:
SELECT column_name, COUNT(column_name) FROM table_name GROUP BY column_name HAVING COUNT(column_name) > 1;
3、执行结果:
该查询将列出每个重复值及其出现的次数。
(图片来源网络,侵权删除)
二、使用DISTINCT 关键字
1、基础用法:
DISTINCT 用于返回唯一不同的值。
2、示例:
SELECT DISTINCT column_name FROM table_name;
3、执行结果:
显示无重复的记录列表。
(图片来源网络,侵权删除)
三、使用SELF JOIN
1、基础用法:
表可以与自身进行连接,基于特定条件来查找重复行。
2、示例:
SELECT t1.column_name FROM table_name t1 JOIN table_name t2 ON t1.column_name = t2.column_name AND t1.primary_key != t2.primary_key;
3、执行结果:
显示所有重复行。
四、使用EXISTS 子查询
1、基础用法:
通过子查询检查是否存在满足某些条件的记录。
2、示例:
SELECT column_name
FROM table_name t1
WHERE EXISTS (SELECT 1
FROM table_name t2
WHERE t1.column_name = t2.column_name
AND t1.primary_key != t2.primary_key);
3、执行结果:
显示所有重复的列值。
使用窗口函数
1、基础用法:
窗口函数可以在每行的上下文中进行计算,适用于复杂的重复值检测。
2、示例:
SELECT column_name FROM ( SELECT column_name, ROW_NUMBER() OVER(PARTITION BY column_name ORDER BY column_name) as row_num FROM table_name ) t WHERE t.row_num > 1;
3、执行结果:
显示每个重复组的额外行(除第一行以外的所有行)。
方法各有优势,可根据具体需求和数据结构选择最合适的方法,掌握这些技能将有助于提高数据处理的效率和准确性。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/12753.html
