
sql,SELECT name, COUNT(*) as count,FROM table_name,GROUP BY name,HAVING count > 1;,“在数据库中,我们经常需要查找重复的数据,这可能是因为数据输入错误、合并不同来源的数据或者进行数据分析时需要识别重复记录,SQL提供了多种方法来查询重复的数据,以下是一些常用的方法:
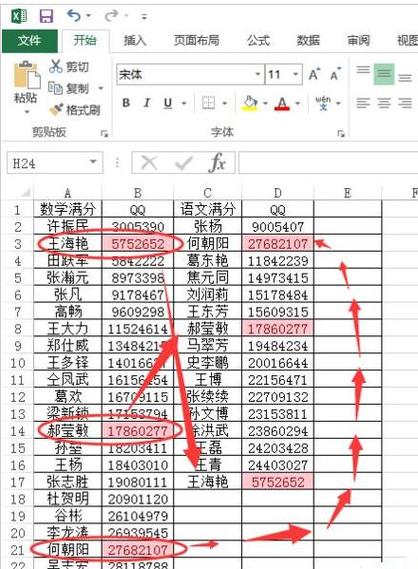
1. 使用GROUP BY和HAVING子句
这种方法是最常见的,它允许你根据一个或多个列对数据进行分组,并找出那些具有超过一个记录的组。
SELECT column_name1, column_name2, ..., COUNT(*) FROM table_name GROUP BY column_name1, column_name2, ... HAVING COUNT(*) > 1;
假设我们有一个名为employees的表,其中包含员工的信息,包括id,first_name,last_name等,如果我们想找出有相同姓名的员工,我们可以这样写:
SELECT first_name, last_name, COUNT(*) FROM employees GROUP BY first_name, last_name HAVING COUNT(*) > 1;
这将返回所有具有相同名字的员工及其出现的次数。
2. 使用窗口函数
窗口函数是一种高级功能,允许你在结果集的每一行上执行聚合操作,这对于查找重复数据非常有用。
SELECT column_name1, column_name2, ..., COUNT(*) OVER (PARTITION BY column_name1, column_name2, ...) as count FROM table_name;
使用窗口函数查找重复的员工姓名:
SELECT first_name, last_name, COUNT(*) OVER (PARTITION BY first_name, last_name) as count FROM employees;
这将返回所有员工的姓名以及每个姓名的出现次数。
3. 使用自连接
自连接是将表与自身连接的一种技术,它可以用于查找表中的重复记录。
SELECT a.column_name1, a.column_name2, ... FROM table_name a, table_name b WHERE a.column_name1 = b.column_name1 AND a.column_name2 = b.column_name2 AND a.id <> b.id;
查找具有相同姓名的员工:
SELECT a.first_name, a.last_name FROM employees a, employees b WHERE a.first_name = b.first_name AND a.last_name = b.last_name AND a.id <> b.id;
这将返回所有具有相同姓名的员工。
常见问题与解答
问题1: 如何只显示重复数据的第一次出现?
解答: 如果你想只显示重复数据的第一次出现,你可以在上述查询的基础上添加LIMIT 1,请注意,这将依赖于数据库的排序行为,因此可能不是跨所有数据库都有效的方法,一种更可靠的方法是使用窗口函数,并在结果集中过滤出计数大于1的行。
问题2: 如何修改查询以查找具有特定条件的重复数据?
解答: 要查找具有特定条件的重复数据,你可以在WHERE子句中添加额外的条件,如果你只想查找姓氏为"Smith"的员工中的重复姓名,你可以这样做:
SELECT first_name, last_name, COUNT(*) FROM employees WHERE last_name = 'Smith' GROUP BY first_name, last_name HAVING COUNT(*) > 1;
这将返回所有姓氏为"Smith"且有重复姓名的员工及其出现的次数。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/15394.html
