
在大数据时代,随着数据量的激增,单个数据库表可能无法有效地处理海量数据,为了提高查询效率和系统性能,数据库管理员通常会采用分表(sharding)技术来分散数据到多个表中,本文将详细介绍数据库分表的概念、实施步骤以及如何进行查询。
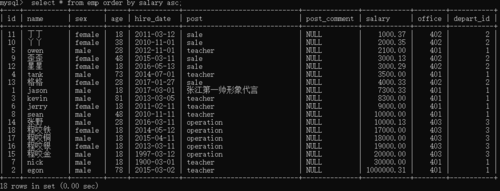

分表概念
分表是数据库水平切分的一种方式,它将一个逻辑上的大表分割成多个小表,每个小表称为一个分片或子表,它们分布在不同的数据库服务器上,以此来提高查询效率和吞吐量。
分表策略
1. 范围分片(range sharding)
根据数据的范围进行分片,如按照时间、id范围等。
2. 哈希分片(hash sharding)
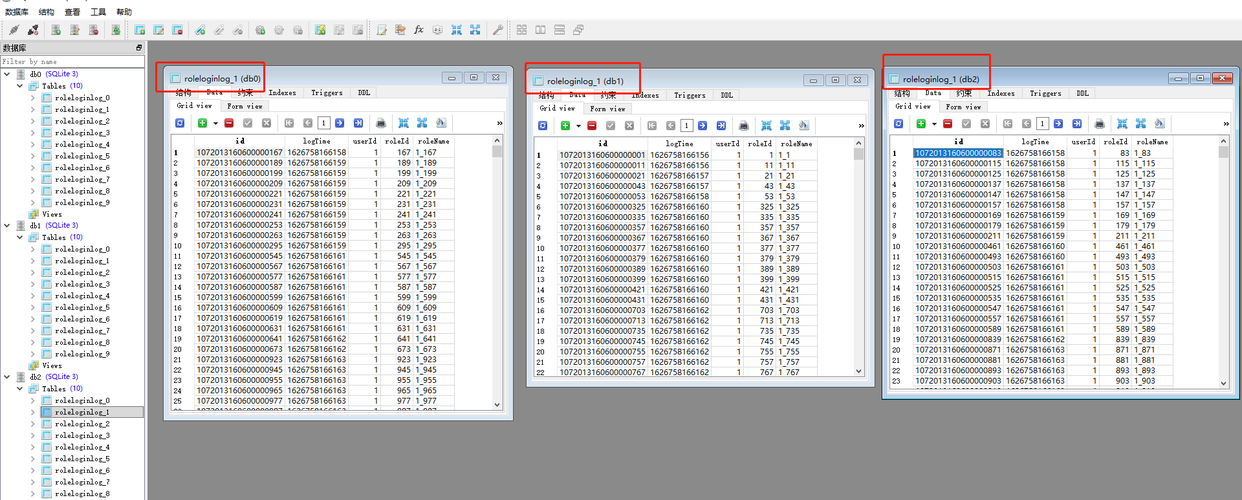
通过哈希函数将数据均匀分布到不同的分片中。
3. 目录分片(directorybased sharding)
维护一个目录表,记录每个记录所在的分片信息,查询时先查目录表。
4. 复合分片(compound sharding)
结合以上几种策略进行更复杂的分片设计。
实施步骤
1. 选择合适的分片键
确定用于分片的字段,通常是查询中最频繁使用的字段。
2. 设计分片策略
根据数据特征和访问模式选择最合适的分片策略。
3. 数据迁移
将现有数据按照分片策略重新分布到各个分片中。
4. 修改应用逻辑
更新应用程序以适应新的分片结构,包括数据插入、查询、更新和删除操作。
5. 监控与优化
持续监控分片的性能并作出必要的调整。
分表查询方法
1. 单表查询
直接对特定分片执行查询操作。
2. 多表联合查询
如果查询涉及多个分片,需要跨分片执行联合查询。
3. 使用中间件
一些数据库中间件支持分表查询,可以简化跨分片查询的复杂性。
相关问题与解答
问题1:分表后如何保证数据的一致性?
答:确保数据一致性通常需要在应用层实现事务管理,或者利用数据库本身的分布式事务特性,对于不支持分布式事务的数据库,可以采用两阶段提交等协议来保证操作的原子性。
问题2:分表是否会影响数据库的写入性能?
答:分表可以提高写入性能,因为数据被分散到多个表中,减少了单一表的写入压力,这也取决于分片策略和数据分布的均匀性,如果某些分片接收到的写入请求远多于其他分片,可能会导致热点问题,影响整体性能,合理的分片设计和负载均衡策略对于保持高性能至关重要。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/17637.html