
基本原理
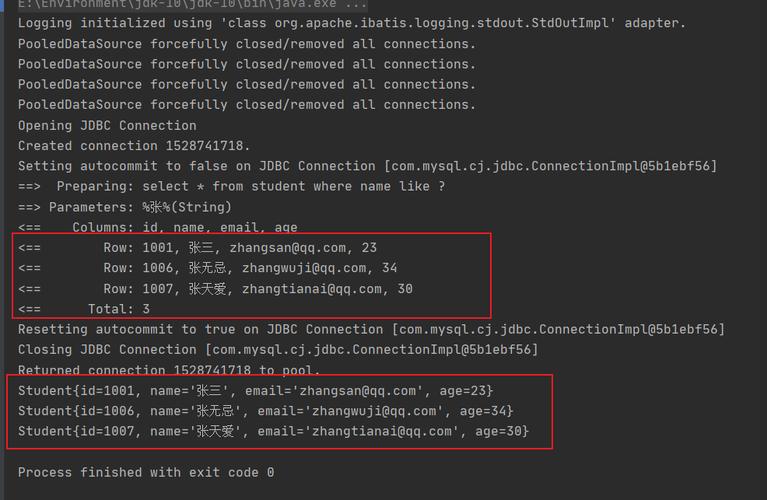
模糊查询主要通过SQL中的LIKE关键字实现,它允许在查询语句中使用特殊字符(如%)来代表任意数量的字符。%放置在不同的位置,可以代表字段开始、结束或中间部分的任何文本,LIKE ‘XX%’ 会选取所有以“XX”开头的字段值,而LIKE ‘%XX’ 则选取所有以“XX”结尾的值。
变量使用
在实际的应用中,往往需要根据用户的输入或程序中产生的动态数据来执行查询,这时候就需要在LIKE语句中使用变量,具体操作中,变量可以被嵌入到LIKE语句的模板中,通过特定的格式来动态生成查询条件。
1、直接拼接:最简单的方式是将变量值直接拼接到LIKE语句中。"SELECT * FROM table WHERE field LIKE ‘%" + var + "%’",这种方法简单直接,但需要注意防范SQL注入的风险。
2、参数化查询:使用参数化查询是防止SQL注入并提高查询效率的推荐做法,大多数现代数据库接口都支持参数化查询,可以在不直接构造SQL语句的情况下,安全地插入变量值。
查询模式
1、前置模糊查询:适用于知晓文字起始部分的场景,模型号以“PSM24W”开头的产品,可以使用LIKE ‘PSM24W%’进行查询。
2、后置模糊查询:当需要根据文本的结尾部分进行查询时使用,如型号信息以“RFA1”则使用LIKE ‘%RFA1’。
3、中间模糊查询:适用于只知中间部分字符的情况,任意位置包含“24W”的模型可以采用LIKE ‘%24W%’。
高效利用
1、避免全表扫描:尽量在LIKE语句中使用其他条件限制结果集的大小,如结合WHERE子句中的其他条件,或合理使用TOP语句限制返回的行数。
2、索引优化:虽然LIKE语句本身难以利用传统的索引,但通过合理的数据库设计,如使用全文索引,可以提高包含LIKE语句的查询性能。
3、使用存储过程:在一些复杂的查询场景中,可以考虑将模糊查询逻辑封装在存储过程中,减少客户端与数据库服务器之间的数据传输,同时提高复用性和可维护性。
实际应用
1、Web应用:用户输入的搜索词常常需要在数据库中进行模糊匹配,如电商平台中根据商品名或描述进行搜索。
2、数据分析:数据分析师可能需要在大型的文本数据集中查找包含特定模式或关键词的记录。
3、安全监控:监控系统日志时,需要根据部分日志信息模糊匹配可能的安全事件或错误。
相关问题与解答
Q1: SQL模糊查询中%和_的区别是什么?
A1: 在SQL的LIKE语句中,%用于表示任意数量的字符(包括零个),而_则代表一个任意字符,LIKE ‘A_’ 将匹配到任何以“A”开头并且之后恰好有一个字符的数据。
Q2: 如何在Java中使用PreparedStatement进行模糊查询?
A2: 在Java中,可以使用PreparedStatement的setString方法设置带占位符的SQL查询语句中的参数。“SELECT * FROM users WHERE userName LIKE ?",然后调用pstatement.setString(1, "%" + userInput + "%")来设定具体的模糊匹配参数。
SQL模糊查询提供了强大的数据筛选功能,尤其是通过配合变量使用,极大地增强了查询的灵活性和适用性,通过合理地运用不同的查询模式和优化策略,可以在各种应用场景下高效地获取所需数据。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/17971.html
