
1. 多表查询产生重复数据的原因
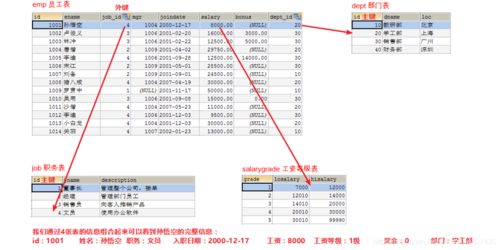
1.1 关联到非唯一字段
在进行多表查询时,如果JOIN操作涉及到的字段不是唯一的,就可能导致结果集中出现重复的记录,这是因为当一个表中的多个记录与另一个表的同一个记录匹配时,每次匹配都会产生一个新的结果集行。
1.2 一对多关系产生的笛卡尔积
在一对多(onetomany)的数据表关系中,主表的一条记录可能与子表的多条记录相关联,在这种情况下,直接的JOIN操作会导致笛卡尔积的产生,从而使得查询结果中存在大量重复的主表数据。
2. 解决多表查询重复数据的方法
2.1 使用DISTINCT关键字
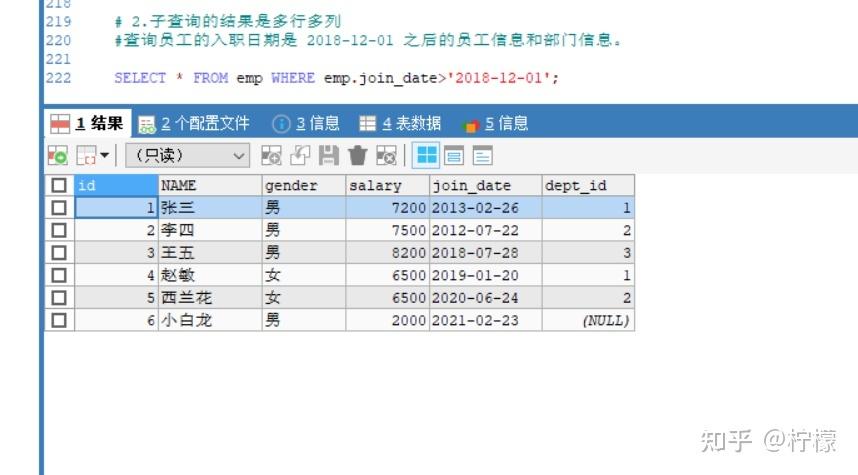
在SQL查询中加入DISTINCT关键字可以有效地去除查询结果中的重复记录,此方法适用于对查询结果中的全部或部分列需要去重的场景。
2.2 应用GROUP BY子句
通过GROUP BY子句可以将结果集按照一个或多个列进行分组,从而避免因直接关联查询而产生的重复数据问题,这在汇总类型的查询中尤为有用。
2.3 选择合适的JOIN类型
根据实际的数据关系和查询需求,选择合适的JOIN类型(如INNER JOIN、LEFT JOIN、RIGHT JOIN等)可以减少不必要的数据重复,特别是当使用LEFT JOIN或RIGHT JOIN时,应注意右表或左表中的记录是否会导致结果集中的不必要的重复。
2.4 利用子查询
通过子查询的方式,可以先对关联的数据进行筛选或预处理,减少参与JOIN操作的记录数,从而间接地减少结果集中的重复数据。
2.5 使用窗口函数
在一些复杂的查询中,窗口函数可以用来对结果集进行更精细的排序和去重,尤其适用于需要根据某个字段进行去重但保留其他字段信息的场景。
3. 推荐的查询策略和习惯
3.1 检查关联字段的唯一性
在设计查询时,检查涉及JOIN操作的字段是否具有唯一性是一个重要的步骤,确保这些字段具有良好的唯一约束可以提高查询的准确性和效率。
3.2 优化数据库设计
合理设计数据库表结构,尤其是表之间的关系和索引,可以从根本上减少查询中出现重复数据的风险,适当地使用外键约束和索引可以显著提高查询性能和结果的准确性。
4. 相关问题与解答
4.1 在使用DISTINCT关键字时,能否只对部分列进行去重?
是的,DISTINCT关键字可以用在查询的一部分列上,不需要对所有返回的列都进行去重,这样可以灵活处理那些只需要部分列唯一的查询需求。
4.2 GROUP BY子句和DISTINCT关键字在去重上有何不同?
虽然GROUP BY和DISTINCT都可以用来去除查询结果中的重复记录,但它们的用法和目的有所不同,DISTINCT主要用于去除完全重复的行,而GROUP BY则通常用于根据某列或某些列的值将结果集分组,常与聚合函数一起使用来对每个组进行计算或汇总。
在小编总结中,掌握和运用上述去除重复数据的策略,对于提高数据库查询的准确性和效率至关重要,通过合理的数据库设计、明智地选择查询策略以及养成良好的SQL编写习惯,可以有效地避免在多表查询中产生重复数据的问题。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/21956.html
