
多表查询基础
多表查询涉及将两个或多个表通过某个公共字段(通常是外键)连接起来,以便于在一个查询中获取来自这些表的相关数据。
表连接类型
内连接(inner join): 只返回两个表中匹配的行。
左连接(left join): 返回左表中的所有行,即使右表中没有匹配的行。
右连接(right join): 返回右表中的所有行,即使左表中没有匹配的行。
全连接(full join): 当左表或右表中的行在另一侧没有匹配时,返回左表和右表中的所有行。
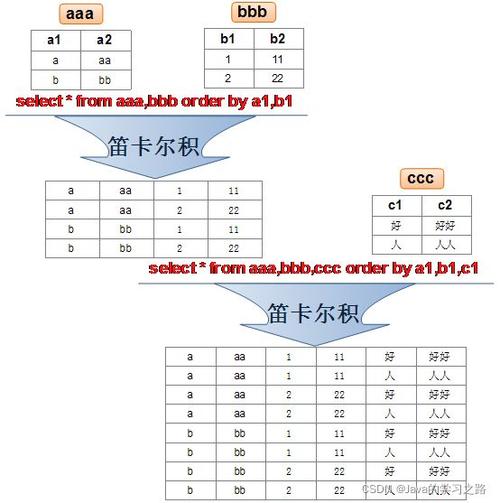
使用 distinct
distinct 关键字用于移除查询结果中的重复行,确保每个返回的行都是唯一的。
多表查询 distinct 示例
假设我们有两个表:orders 和customers。
orders 表:
| order_id | customer_id | order_date |
| 1 | 101 | 20230101 |
| 2 | 102 | 20230102 |
| 3 | 101 | 20230105 |
| 4 | 103 | 20230106 |
customers 表:
| customer_id | name | country |
| 101 | alice | usa |
| 102 | bob | canada |
| 103 | carol | mexico |
如果我们想找出所有下过订单的不同客户的名字,我们可以执行以下查询:
select distinct c.name from customers c inner join orders o on c.customer_id = o.customer_id;
这个查询会返回以下结果:
| name |
| alice |
| bob |
| carol |
优化多表查询
当涉及到大量数据时,进行多表查询可能会影响性能,以下是一些优化技巧:
1、索引: 确保连接条件上的字段被索引,以加快查询速度。
2、限制结果集大小: 使用 limit 子句来限制返回的行数。
3、分析执行计划: 大多数数据库管理系统都提供了解释查询执行计划的工具,这可以帮助你理解查询是如何执行的,并找到潜在的瓶颈。
相关问题与解答
q1: 如果我只想看到下过至少两次订单的客户名称,应该如何修改查询?
a1: 你可以使用 group by 子句结合 having 子句来实现这一点,如下所示:
select c.name from customers c inner join orders o on c.customer_id = o.customer_id group by c.name having count(o.order_id) >= 2;
这个查询首先根据客户名称分组,然后使用 having 子句筛选出至少有两笔订单的客户。
q2: 如果在多表查询中使用 distinct,性能是否会下降?
a2: 是的,使用 distinct 通常会导致性能下降,因为数据库需要额外处理来识别和移除重复的行,如果数据集很大,这种影响可能更加明显,为了提高性能,可以考虑优化查询结构,比如减少连接的表数量、仅选择需要的字段、或者使用 where 子句来限制结果集的大小,确保相关的字段有适当的索引也是非常重要的。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/33930.html
