
robots文件是用于指导爬虫程序访问权限的文本文件,通常位于网站根目录。它包含Useragent、Disallow等指令,通过指定特定爬虫和路径规则来控制网站内容的抓取。正确配置robots文件有助于保护隐私,优化SEO,并减轻服务器负担。
| robots.txt文件基础 | |
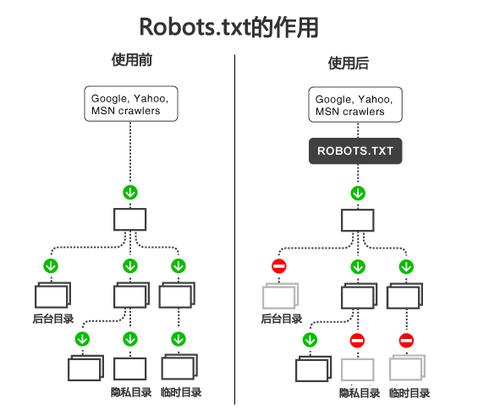
| 定义与作用 | robots.txt是一种位于网站根目录下的ASCII编码文本文件,主要作用是指导搜索引擎的网络爬虫(或称漫游器)在访问网站时,哪些内容是可以抓取(即允许收录),哪些是禁止抓取的。 |
| 重要性 | 通过正确配置robots.txt,网站管理者可以有效控制网站内容的公开程度,防止敏感信息被搜索引擎索引,同时也帮助搜索引擎更高效地抓取允许被收录的页面。 |
| robots.txt文件结构 | |
| 基本语法 | robots.txt文件通过简单的语法指示搜索引擎爬虫的行为,使用”Useragent”指定爬虫的名称,随后用”Disallow”声明不允许抓取的路径,用”Allow”声明允许抓取的路径。 |
| 案例分析 | 若文件中包含以下内容: “useragent: * Disallow: /private/ Allow: /public/“ 这意味着所有搜索引擎爬虫都不允许抓取’/private/’路径下的任何内容,但允许抓取’/public/’路径下的内容。 |
| 高级应用技巧 | |
| 动态管理 | 网站管理员可以通过修改robots.txt文件来动态调整搜索引擎爬虫的行为,如临时禁止某个页面的收录,或者恢复之前禁止的页面。 |
| 优化抓取效率 | 合理配置robots.txt可以帮助搜索引擎爬虫减少不必要的抓取尝试,从而提高网站的抓取效率和资源利用。 |
| robots.txt文件最佳实践 | |
| 避免屏蔽过多内容 | 过度使用Disallow指令可能会阻止有价值内容的收录,降低网站的可见性,应仅对真正需要保护的内容使用Disallow。 |
| 频繁更新检查 | 定期检查并更新robots.txt文件,确保其配置符合当前网站的保护需求和SEO策略。 |
| 相关问题与解答 | |
| Q1: robots.txt是否对所有搜索引擎都有效? | A1: robots.txt是一个通用的标准,大多数搜索引擎都会遵守这个协议,但不是强制性标准,具体效果取决于各个搜索引擎的实现方式。 |
| Q2: 如果网站没有robots.txt文件会怎么样? | A2: 如果网站没有robots.txt文件,大多数搜索引擎会默认抓取所有可以访问的页面,但这也取决于具体的搜索引擎策略。 |
通过上述详细解析,我们可以看到robots.txt文件在网站内容管理和搜索引擎优化中扮演着重要的角色,正确理解和运用这一文件不仅可以保护网站内容不被随意抓取,还可以提高网站的搜索引擎友好度,希望本文能帮助您更好地掌握robots.txt的使用技巧和注意事项。

(图片来源网络,侵权删除)
(图片来源网络,侵权删除)
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/35277.html