
1、使用 GROUP BY 和 HAVING 子句
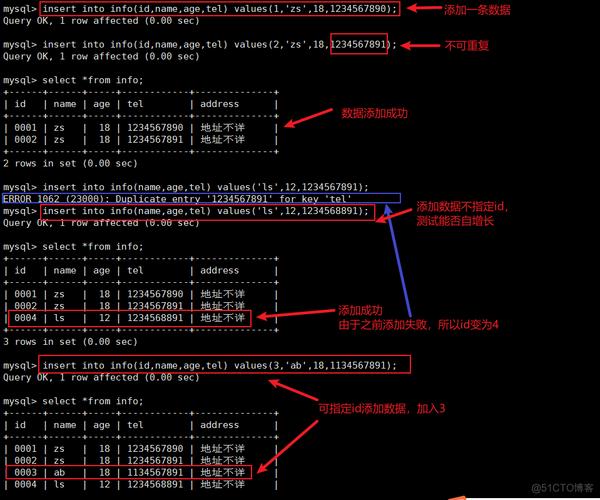

理论基础:GROUP BY 语句用于将具有相同值的行分组在一起,而HAVING 子句则用于过滤这些组,只留下那些符合特定条件的组,例如组内行数大于1的组,即存在重复值的组。
应用场景:当需要找出表中某单个列字段重复的数据时,这种方法非常适用,它可以快速地显示出哪些字段值是重复的,以及每个重复值对应的记录数。
优缺点:此方法简单高效,特别适合于初步筛查大量数据中的重复记录,它不能显示重复记录的全部详细信息,仅能显示重复的字段和次数。
2、使用 DISTINCT 关键字
理论基础:DISTINCT 关键字用于返回唯一不同的值,在查询中添加DISTINCT,可以确保结果集中不包含重复的行。
应用场景:适用于需要快速获取不重复数据的场景,如统计分析等。
优缺点:使用DISTINCT 可以直观地看到不重复的数据,但它不直接显示哪些记录是原始数据中的重复部分,通常需要与其他查询技巧结合使用来定位重复记录。
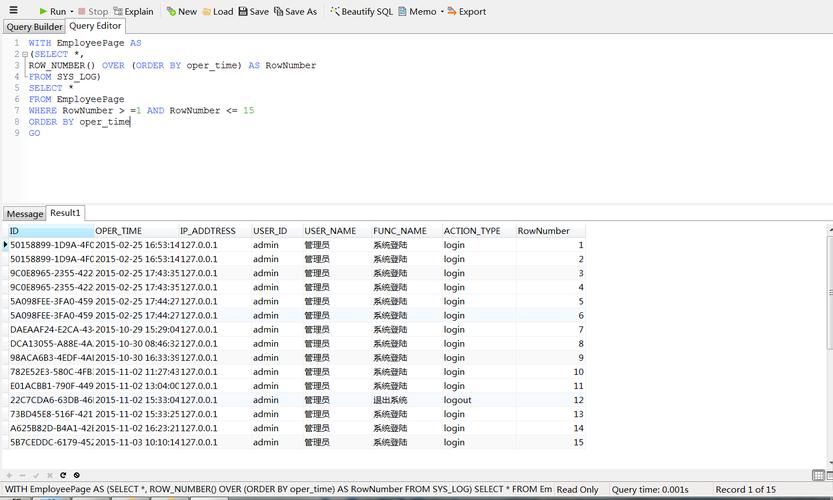
3、使用窗口函数
理论基础:窗口函数提供了一种在一组相关行上进行计算的方式,这组行称为“窗口”,通过窗口函数,可以轻松地对数据进行排序、比较和计算,从而找到重复的数据。
应用场景:适用于复杂的重复数据检测需求,如计算每组重复值的排名或计数。
优缺点:窗口函数功能强大,但语法相对复杂,对于初学者可能有一定的学习曲线。
4、使用 SELF JOIN
理论基础:自连接(SELF JOIN)是将表与其自身连接的一种方式,可以用来比较表中的记录,并找出重复的记录。
应用场景:当需要比较表中的记录以查找完全相同或部分相同的记录时,自连接是一个非常有用的技术。
优缺点:自连接能够提供非常灵活的比较条件,但可能会增加查询的复杂度和执行时间,特别是在处理大表时。
5、使用 EXISTS 子查询
理论基础:EXISTS 子查询用来检查子查询是否返回任何行,通过这种方式,可以有效地找到那些在子查询中存在匹配的记录,即重复的记录。
应用场景:适合于需要基于更复杂条件检查重复的情况,例如两个表中的记录是否重复。
优缺点:这种方法灵活且功能强大,但可能会使查询变得复杂,需要更多的数据库资源。
理解各种方法的特点和适用场景,可以帮助数据库管理员选择最适合当前需求的解决方案,根据实际的数据结构和业务需求灵活运用上述方法,可以有效地解决重复数据问题,保持数据的整洁和准确性。
相关问题与解答
Q1: 在执行 SQL 查询时,如何确定哪种方法最适合我的需要?
A1: 选择最合适的方法取决于具体的数据结构、数据量大小以及所需执行的操作类型,如果只是简单地查找某列的重复值,使用 GROUP BY 和 HAVING 子句是最直接有效的方法,如果需要进行更复杂的数据分析或处理,考虑使用窗口函数或自连接,如果是基于多个条件检查重复,可以考虑使用 EXISTS 子查询。
Q2: 处理重复数据有哪些最佳实践?
A2: 定期检查和清理数据是预防数据冗余的关键,根据数据的重要性和敏感性制定合理的数据管理策略,在删除任何数据之前,确保已经备份了原始数据,合理利用索引和优化查询语句可以提高效率,减少不必要的资源消耗。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/4134.html