
在数据库管理中,识别和处理重复数据至关重要。本文将介绍几种有效的MySQL查询方法来查找重复数据,并通过实例帮助深入理解这些技术。
1. 使用GROUP BY 和 HAVING 子句
方法描述:
通过组合GROUP BY和HAVING子句,可以有效地找出表中的重复记录,这种方法不仅适用于查找单个字段的重复值,还可以扩展到多个字段。
实际应用:
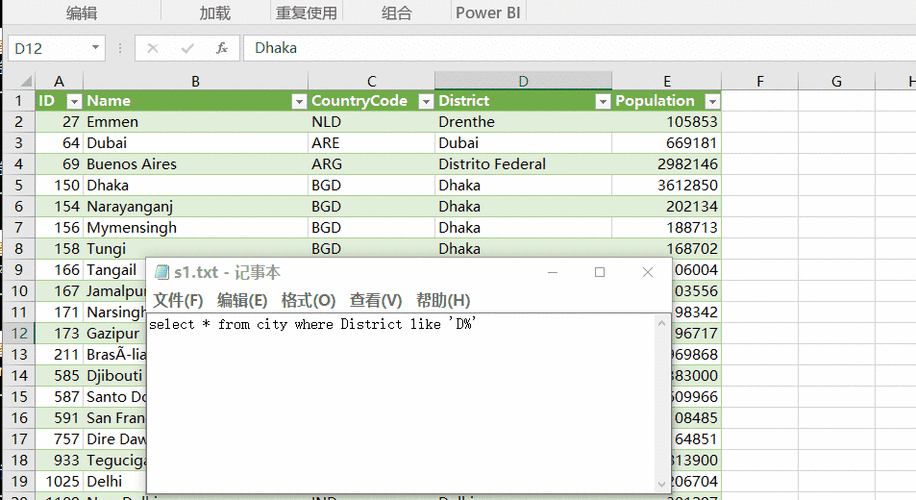
假设有一个员工表(employee),我们想找出其中重复的姓名,可以使用以下查询语句:
SELECT name, COUNT(*) FROM employee GROUP BY name HAVING COUNT(*) > 1;
这个查询首先按name字段分组,然后使用HAVING子句过滤出计数大于1的组,即存在重复的姓名。
2. 利用JOIN 和 EXISTS 子句
方法描述:
使用自连接或内连接(INNER JOIN)以及EXISTS子句可以更灵活地查询重复数据,尤其是在需要基于多个字段判断重复时。
实际应用:
如果我们要查找员工表中同一部门内具有相同职位的记录,可以使用以下查询:
SELECT e1.* FROM employee e1 INNER JOIN employee e2 ON e1.department = e2.department AND e1.job = e2.job AND e1.id != e2.id
这里通过员工表自身的内连接,根据部门和职位匹配并排除ID相同的记录,从而找到重复的数据。
3. 使用临时表或子查询
方法描述:
当原始数据量大且复杂时,使用临时表或子查询可以简化查询过程并提高效率。
实际应用:
考虑一个较复杂的查询,比如我们需要找出同时具有相同地址和电话号码的员工记录,可以通过创建临时表来简化查询:
CREATE TEMPORARY TABLE temp_employee AS SELECT * FROM employee; SELECT * FROM temp_employee e1, temp_employee e2 WHERE e1.address = e2.address AND e1.phone = e2.phone AND e1.id != e2.id;
此查询首先创建一个临时表,然后通过两次自连接操作找出满足条件的重复记录。
介绍了三种在MySQL中查询重复数据的主要方法,每种方法都有其适用的场景和特点,可以根据具体需求选择最合适的方法。
4. 相关问题与解答
Q1: 如果我想删除找到的重复记录,应该怎么做?
A1:
删除重复记录通常可以在查询的基础上进行,如果使用GROUP BY和HAVING找到了重复的姓名,可以结合DELETE语句和JOIN来实现删除:
“`sql
DELETE e1 FROM employee e1
INNER JOIN (
SELECT name
FROM employee
GROUP BY name
HAVING COUNT(*) > 1
) e2 ON e1.name = e2.name;
“`
这个操作会删除员工表中那些姓名出现在子查询结果中的记录,即只保留每个姓名的一条记录。
Q2: 如何防止未来数据输入时的重复?
A2:
防止数据重复的最佳实践是在数据库设计阶段设置适当的约束,可以为员工表的name字段设置唯一索引(UNIQUE INDEX),这样数据库管理系统就会自动拒绝任何导致该字段重复的插入或更新操作:
“`sql
ALTER TABLE employee ADD UNIQUE (name);
“`
确保应用程序层的数据处理逻辑也能有效验证和避免重复数据的输入。
掌握如何在MySQL中查询和处理重复数据是数据库管理的基本技能之一,通过上述介绍的方法,您可以有效地识别、分析并处理数据库中的重复记录,保持数据的准确性和完整性。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/42746.html
