
sql查询用于识别数据库表中的重复记录,这是维护数据整洁和提高性能的关键步骤。通过具体示例,本文将展示如何利用sql语句有效地查找出这些重复数据项。
背景假设
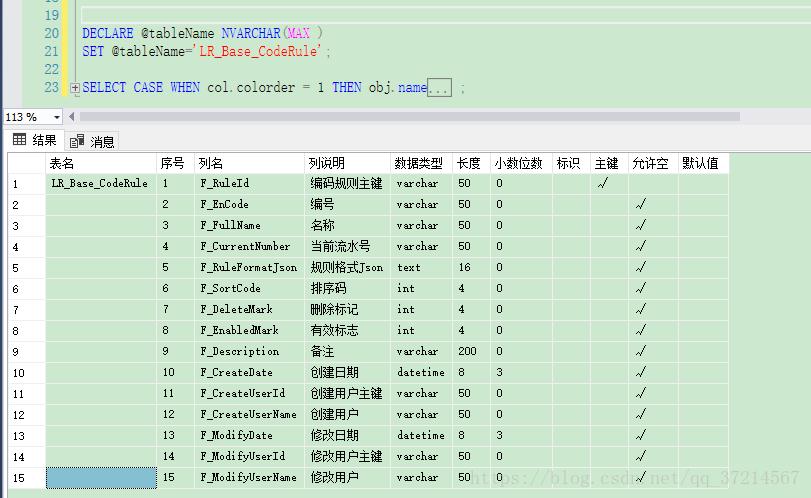

假设我们有一个名为employees的表,其中包含员工的详细信息,这个表有以下几个字段:
id: 员工的唯一标识符(主键)
first_name: 员工的名字
last_name: 员工的姓氏
email: 员工的电子邮件地址
department: 员工所在的部门
我们需要找出表中哪些员工的邮箱地址是重复的。
sql查询重复数据的步骤
1. 使用group by和having子句
一种常见的方法是使用group by和having子句来识别重复项,以下是一个示例查询,它返回每个邮箱地址的出现次数,并过滤出那些出现次数大于1的邮箱地址:
select email, count(*) as count from employees group by email having count > 1;
这个查询会列出所有重复的邮箱以及它们出现的次数。
2. 使用窗口函数
如果你想要查看每个重复邮箱对应的所有员工记录,可以使用窗口函数count() over(),以下是一个示例查询:
select id, first_name, last_name, email, department,
count(email) over (partition by email) as email_count
from employees;
这个查询会显示每条员工记录,以及与他们共享相同邮箱地址的员工数量。
3. 删除或更新重复数据
一旦确定了重复的数据,你可以选择删除或更新这些记录,如果你想保留每个邮箱地址的最新一条记录,你可以先确定每组重复数据中的最大id(假设id是自增的),然后删除其他记录:
delete from employees where id not in ( select max(id) from employees group by email );
这个查询会删除除每个邮箱地址最新记录之外的所有记录。
单元表格
| step | description | example query |
| 1 | 使用group by和having子句查找重复邮箱 | select email, count(*) as count from employees group by email having count > 1; |
| 2 | 使用窗口函数查看每个重复邮箱对应的所有记录 | select *, count(email) over (partition by email) as email_count from employees; |
| 3 | 删除或更新重复数据 | delete from employees where id not in (select max(id) from employees group by email); |
相关问题与解答
q1: 如果表中有很多列,我如何快速找出哪些列可能包含重复数据?
a1: 你可以使用如下查询来检查表中各列的重复情况:
select column_name, count(distinct column_name) as distinct_count, count(*) as total_count from table_name group by column_name having total_count > distinct_count;
将column_name替换为你想要检查的列名,将table_name替换为你的表名,这个查询会返回每列的不重复计数和总计数,从而帮助你发现哪些列存在重复值。
q2: 如何避免在将来的数据录入中产生重复数据?
a2: 为了避免未来的数据录入中产生重复数据,可以采取以下措施:
1、设置唯一约束:在数据库设计阶段,对那些需要保持唯一的字段设置唯一约束(unique constraint),这可以在数据库层面防止插入重复数据。
2、预检查:在数据插入前进行预检查,确保新数据不会与现有数据冲突。
3、使用事务:确保数据操作的原子性、一致性、隔离性和持久性,在事务中执行数据插入操作,如果检测到冲突则回滚事务。
4、用户界面验证:在用户输入数据的界面上实施前端验证,阻止重复或无效数据的提交。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/43341.html