
数据库查询重复数据通常使用SQL语句,通过GROUP BY和HAVING子句来识别和删除重复记录。使用SELECT DISTINCT可以获取不重复的数据;而使用GROUP BY结合COUNT函数,可以找出重复的记录。
理解重复数据
在数据库中,重复数据是指出现多次的相同或相似数据,这些数据可能是由于数据输入错误、数据规范化不足、数据合并等原因产生的,在一个包含“名字”和“年龄”列的表中,如果存在多条记录具有相同的名字和年龄,那么这些记录就可以被视为重复数据。
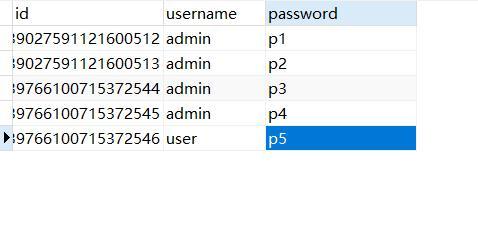
查询重复数据的策略
1、使用GROUP BY和HAVING子句:这是一个基础策略,适用于简单的重复数据查找,通过GROUP BY对一个或多个字段进行分组,然后使用HAVING子句筛选出记录数大于1的组,就可以找出重复记录。
2、使用DISTINCT和COUNT组合:这个策略可以用来查找多列的复合重复数据,通过对多列进行去重并计数,可以找出在多列上同时重复的数据。
3、使用临时表:在复杂的场景下,可以使用临时表来存储需要比较的列,然后使用GROUP BY和HAVING子句来找到重复数据。
4、使用自连接:自连接是查找重复记录的另一种方法,通过将表与自身连接,可以比较表中的记录,找出重复的行。
5、使用窗口函数:窗口函数提供了一种更高级的方式来查找重复记录,使用ROW_NUMBER()窗口函数,可以为每一组记录生成一个唯一的序号,从而识别重复记录。
处理重复数据的策略
1、删除重复数据:最直接的方法是删除重复记录,使用SQL查询可以轻松实现这一点。
2、合并重复数据:在某些情况下,删除重复记录并不是最佳选择,特别是当每条记录都包含有价值的信息时,这时,可以通过合并重复记录来保留所有有用信息。
3、标记重复记录:有时,删除或合并重复记录并不符合业务需求,这时,可以通过标记重复记录来区分它们。
预防重复数据的策略
1、设计数据库时考虑数据的唯一性约束:对于不允许重复的列,可以使用UNIQUE约束。
2、插入或更新数据时检查数据是否已经存在:可以先使用SELECT语句检查数据是否存在,如果不存在,再执行INSERT语句。
3、定期检查和清理数据库中的重复数据:这可以通过定期运行上述查询语句来实现。
相关问题与解答
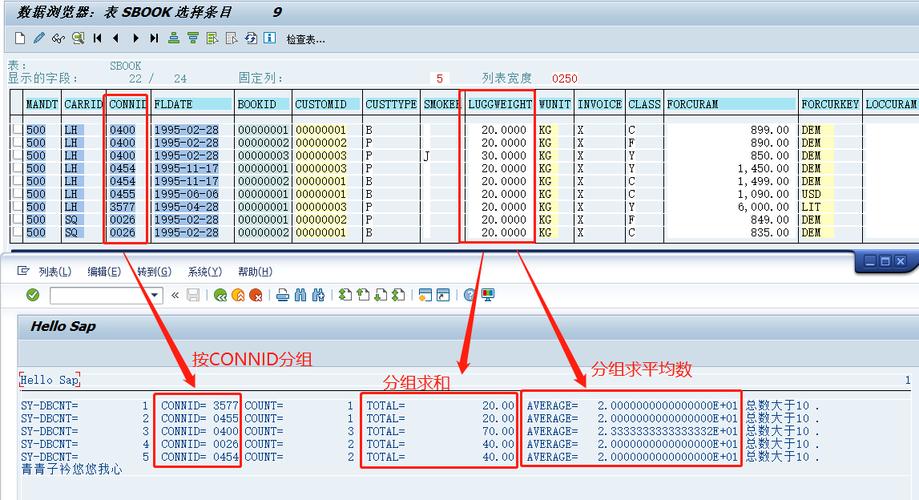
问题1:如何防止数据库中出现重复数据?
答案:可以通过以下几种方式防止数据库中出现重复数据:
1、在设计数据库时,为不允许重复的列设置UNIQUE约束或PRIMARY KEY约束。
2、在插入或更新数据时,先检查数据是否已经存在,如果不存在再执行相应的操作。
3、定期检查和清理数据库中的重复数据,确保数据的一致性和准确性。
问题2:如何处理已经存在的重复数据?
答案:处理已经存在的重复数据的方法有多种,具体取决于业务需求和数据情况:
1、删除重复数据:使用SQL查询删除多余的重复记录。
2、合并重复数据:如果每条记录都包含有价值的信息,可以通过合并重复记录来保留所有有用信息。
3、标记重复记录:在某些情况下,可以通过标记重复记录来区分它们,而不是直接删除或合并。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/45094.html
