
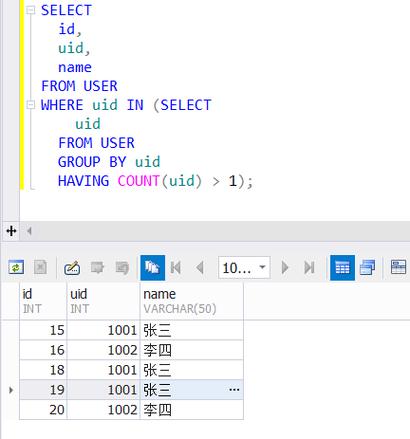
SQL查询重复记录的方法是使用GROUP BY和HAVING子句。使用GROUP BY子句对表中的某个字段进行分组,然后使用HAVING子句筛选出重复次数大于1的记录。
SQL(结构化查询语言)是用于管理和操作关系数据库的编程语言,在实际应用中,数据表中可能会出现重复记录,这些记录不仅会占用存储空间,还可能导致数据分析和处理过程中的错误,查找并处理重复记录显得尤为重要,本文将详细介绍如何使用SQL查询重复记录,并提供相关示例代码。

基本概念
1. 重复记录的定义:
完全重复记录:所有字段值都相同的记录。
部分重复记录:某些关键字段值相同的记录。
2. 常见方法:
使用GROUP BY和HAVING子句:适用于大多数SQL数据库。
使用ROW_NUMBER()函数:适用于支持窗口函数的数据库如SQL Server和PostgreSQL。
使用SELF JOIN:通过表自身连接来查找重复记录。
使用CTE(公共表表达式)和窗口函数:适用于需要复杂查询的情况。
具体方法
1. 使用GROUP BY和HAVING子句:
查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
SELECT * FROM people WHERE peopleId IN (
SELECT peopleId FROM people GROUP BY peopleId HAVING COUNT(peopleId) > 1
);
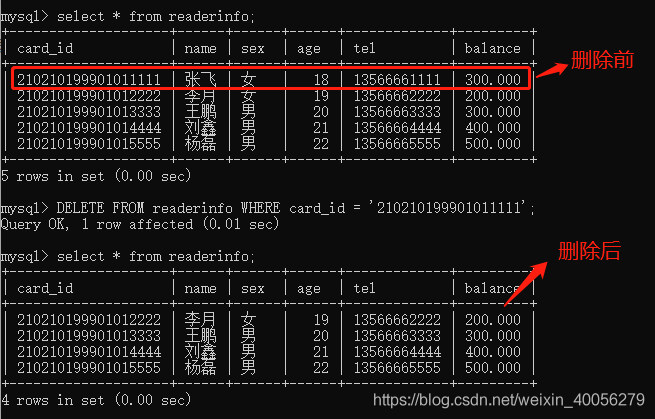
删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
DELETE FROM people WHERE peopleId IN (
SELECT peopleId FROM people GROUP BY peopleId HAVING COUNT(peopleId) > 1
) AND rowid NOT IN (
SELECT MIN(rowid) FROM people GROUP BY peopleId HAVING COUNT(peopleId) > 1
);
2. 使用ROW_NUMBER()函数:
使用ROW_NUMBER()函数查找重复记录
WITH CTE AS (
SELECT col1, col2, ROW_NUMBER() OVER(PARTITION BY col1, col2 ORDER BY (SELECT 0)) AS RowNum
FROM table
)
SELECT col1, col2
FROM CTE
WHERE RowNum > 1;
3. 使用SELF JOIN:
使用SELF JOIN查找重复记录 SELECT t1.col1, t1.col2 FROM table t1 JOIN table t2 ON t1.col1 = t2.col1 AND t1.col2 = t2.col2 WHERE t1.id <> t2.id;
4. 使用CTE和窗口函数:
使用CTE和窗口函数查找重复记录
WITH CTE AS (
SELECT col1, col2, COUNT(*) OVER(PARTITION BY col1, col2) AS DuplicateCount
FROM table
)
SELECT col1, col2, DuplicateCount
FROM CTE
WHERE DuplicateCount > 1;
常见问题与解答
1. 如何查找姓名(Name)字段重复的所有数据?:
SELECT Name, COUNT(*) as '重复次数' FROM A GROUP BY Name HAVING COUNT(*) > 1;
2. 如果还需要按性别(sex)字段进行分组,应如何修改查询?:
SELECT Name, sex, COUNT(*) as '重复次数' FROM A GROUP BY Name, sex HAVING COUNT(*) > 1;
3. 如何删除表中多余的重复记录,只保留rowid最小的记录?:
DELETE FROM people WHERE peopleId IN (
SELECT peopleId FROM people GROUP BY peopleId HAVING COUNT(peopleId) > 1
) AND rowid NOT IN (
SELECT MIN(rowid) FROM people GROUP BY peopleId HAVING COUNT(peopleId) > 1
);
4. 如果需要删除多个字段(例如peopleId和seq)的重复记录,应如何操作?:
DELETE FROM vitae a WHERE (a.peopleId, a.seq) IN (
SELECT peopleId, seq FROM vitae GROUP BY peopleId, seq HAVING COUNT(*) > 1
) AND rowid NOT IN (
SELECT MIN(rowid) FROM vitae GROUP BY peopleId, seq HAVING COUNT(*) > 1
);
5. 如何处理完全重复的记录?:
可以使用DISTINCT关键字来获取不重复的结果集:
SELECT DISTINCT * INTO #Tmp FROM tableName; DROP TABLE tableName; SELECT * INTO tableName FROM #Tmp; DROP TABLE #Tmp;
6. 如果只想保留第一条重复记录,应如何操作?:
假设有重复的字段为Name和Address,要求得到这两个字段唯一的结果集,可以如下操作:
SELECT identity(int,1,1) as autoID, * INTO #Tmp FROM tableName; SELECT min(autoID) as autoID INTO #Tmp2 FROM #Tmp GROUP BY Name, autoID; SELECT * FROM #Tmp WHERE autoID IN(SELECT autoID FROM #tmp2);
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/45777.html