
在数据库管理中,重复数据是一个常见但通常不受欢迎的问题,它们不仅占用额外的存储空间,还可能导致数据分析错误和报告不一致,有效地检测和清除重复记录是维护数据库健康的重要步骤,本文将详细介绍如何在数据库中查询重复数据,并提供一些实用技巧。

什么是重复数据?
重复数据指的是在数据库的一表或多表中存在两条或多条完全相同或者部分字段相同的记录,这些记录可能是由于数据导入错误、系统复制、用户操作失误等原因产生的。
查询重复数据的步骤
1. 确定重复标准
在进行查询之前,首先需要明确什么情况下的数据被认为是重复的,这可能是基于所有字段的完全一致,也可能是某些关键字段的一致(如姓名、电子邮件地址等)。
2. 使用 SQL 查询
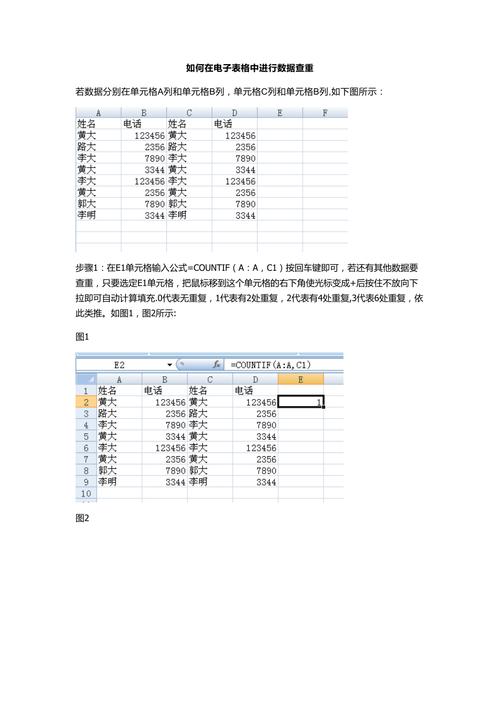
一旦确定了重复的标准,就可以使用 SQL 语句来查询这些重复的数据,以下是一些基本的 SQL 查询示例:
a. 查询完全重复的数据
SELECT column1, column2, COUNT(*) FROM table_name GROUP BY column1, column2 HAVING COUNT(*) > 1;
这个查询会返回那些在所有指定列上完全一致的记录。
b. 查询部分字段重复的数据
SELECT column1, COUNT(*) FROM table_name GROUP BY column1 HAVING COUNT(*) > 1;
这个查询会返回那些在指定列上重复的记录。
3. 分析查询结果
查询结果会展示哪些记录是重复的,以及它们出现的次数,这有助于进一步分析和决定如何处理这些重复数据。
4. 删除或合并重复数据
根据查询结果,可以选择删除重复项或合并它们,合并可能涉及选择一个记录作为主记录,并将相关数据整合到这个记录中。
注意事项
在删除任何数据之前,请确保备份您的数据库。
仔细检查查询条件,以避免误删非重复的数据。
考虑使用事务来确保操作的原子性。
相关问题与解答
Q1: 如果我想找出表中所有列都完全相同的重复记录,我该如何修改上述 SQL 查询?
A1: 如果您想找出所有列都完全相同的重复记录,您需要将所有列名列出在 SELECT 和 GROUP BY 子句中,如果表有 column1, column2, column3 三列,那么查询语句应为:
SELECT column1, column2, column3, COUNT(*) FROM table_name GROUP BY column1, column2, column3 HAVING COUNT(*) > 1;
Q2: 删除重复数据后,如何验证数据库中不再有重复项?
A2: 删除重复数据后,您可以运行同样的查询来确认是否还有重复项,如果没有记录返回,则说明重复数据已被成功删除,定期进行数据完整性检查可以帮助预防未来的重复数据问题。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/4775.html