
数据库中查询重复数据是数据清洗和质量管理的常见需求。有效的方法包括使用SQL语句、哈希值比较、去重算法及第三方工具。这些方法有助于确保数据的一致性和准确性,提高数据质量。
使用GROUP BY和HAVING子句查找重复数据
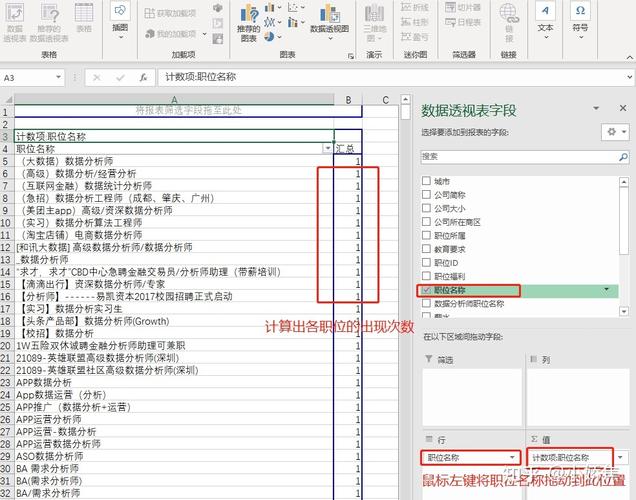

1、基本概念和语法
GROUP BY子句:用于将具有相同值的行分组。
HAVING子句:用于过滤分组后的数据,通常与聚合函数一起使用。
2、实例演示
示例数据表:假设有一个包含员工信息的表employees,其中包含id、name和email字段。
查询语句:
“`sql
SELECT email, COUNT(*)
FROM employees
GROUP BY email
HAVING COUNT(*) > 1;
“`
结果:该查询将返回所有重复的电子邮件地址及其出现的次数。
3、详细解释
GROUP BY子句:将表中的记录按email字段进行分组。
HAVING子句:过滤出那些分组中记录数量大于1的记录,即重复的数据。
其他方法查找重复数据
1、使用窗口函数
示例:
“`sql
SELECT id, name, email
FROM (
SELECT id, name, email,
ROW_NUMBER() OVER (PARTITION BY email ORDER BY id) AS row_num
FROM employees
) subquery
WHERE row_num > 1;
“`
解释:通过ROW_NUMBER()函数为每个分组中的记录排名,然后筛选出行号大于1的记录,即为重复记录。
2、使用自连接
示例:
“`sql
SELECT e1.id, e1.name, e1.email
FROM employees e1
INNER JOIN employees e2 ON e1.email = e2.email
WHERE e1.id <> e2.id;
“`
解释:通过自连接将表与自身进行连接,找出重复的记录。
3、使用EXISTS子句
示例:
“`sql
SELECT e1.id, e1.name, e1.email
FROM employees e1
WHERE EXISTS (
SELECT 1
FROM employees e2
WHERE e1.email = e2.email
AND e1.id <> e2.id
);
“`
解释:使用EXISTS子句检查子查询是否返回任何行,从而找出重复记录。
性能优化和注意事项
1、使用索引:为查找重复数据涉及的字段创建索引,可以显著提高查询性能。
“`sql
CREATE INDEX idx_email ON employees(email);
“`
2、分区表:对于大型表,可以考虑将表分区,以提高查询性能,按日期或其他字段将表分区。
3、数据库优化:确保数据库服务器配置优化,包括内存、存储、网络等资源的合理分配。
4、定期清理和维护:定期清理和维护数据库,以防止数据膨胀和性能下降,删除或归档历史数据,重建索引等。
实际应用中的案例分析
1、电子商务平台中的重复订单:在电子商务平台中,重复订单可能会导致库存管理混乱和客户体验不佳,使用上述方法,可以有效查找和处理重复订单。
2、社交媒体平台中的重复用户:在社交媒体平台中,重复用户可能会导致数据分析和推荐算法的准确性下降,通过查找和合并重复用户,可以提高数据质量和用户体验。
3、财务系统中的重复交易:在财务系统中,重复交易可能会导致财务报表不准确和审计问题,使用上述方法,可以有效查找和处理重复交易。
相关问题与解答
1、如何在数据库中检查是否存在重复数据?
解答:可以使用以下SQL查询语句来检查是否存在重复数据:
“`sql
SELECT column_name, COUNT(*) as count
FROM table_name
GROUP BY column_name
HAVING count > 1;
“`
这将返回所有重复的column_name值以及它们出现的次数。
2、如何删除数据库中的重复数据?
解答:可以使用DELETE语句和子查询来实现删除重复数据。
“`sql
DELETE FROM table_name
WHERE column_name IN (
SELECT column_name
FROM (
SELECT column_name, ROW_NUMBER() OVER(PARTITION BY column_name ORDER BY column_name) AS row_num
FROM table_name
) tmp
WHERE row_num > 1
);
“`
这将删除所有重复行,只保留每个重复值的第一行。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/48829.html