
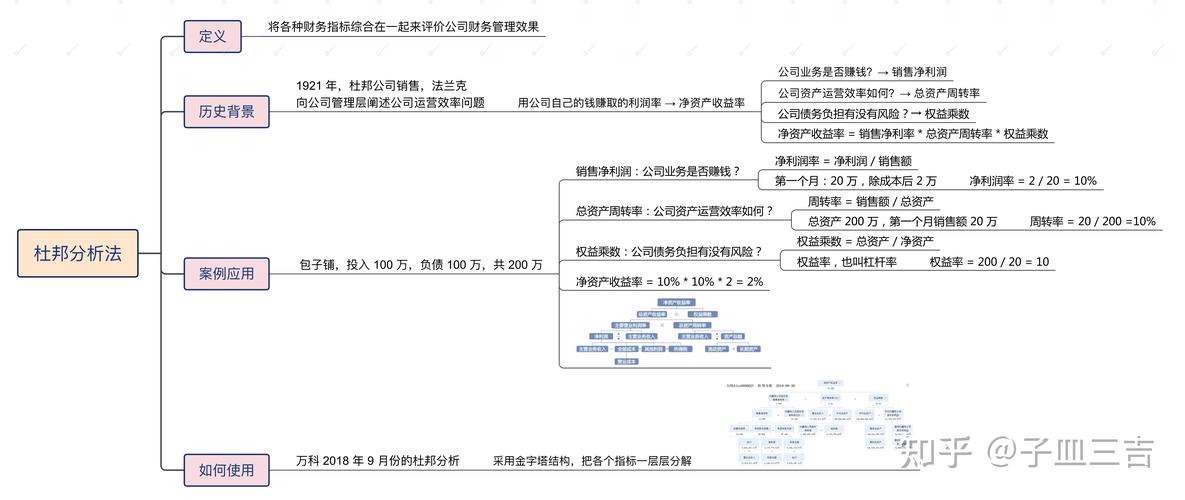
本文详细讲解了在SQL中如何查找重复记录,并提供了实用的示例,旨在帮助读者在数据清洗和分析过程中有效地识别和管理重复数据。
什么是重复记录?
重复记录是指在数据库表中具有相同值的行,这些相同的值通常是指所有列的值都相等,但在某些情况下可能只针对某些关键列进行判断。

如何查找完全重复的记录?
要查找完全重复的记录,可以使用GROUP BY子句结合HAVING子句,假设我们有一个名为employees的表,包含以下列:id,name,age,department。
2.1 示例表结构
| id | name | age | department |
| 1 | John | 30 | IT |
| 2 | Jane | 25 | HR |
| 3 | John | 30 | IT |
| 4 | Alice | 28 | Sales |
| 5 | John | 30 | IT |
2.2 查询重复记录
SELECT name, age, department, COUNT(*) FROM employees GROUP BY name, age, department HAVING COUNT(*) > 1;
2.3 结果
| name | age | department | count |
| John | 30 | IT | 2 |
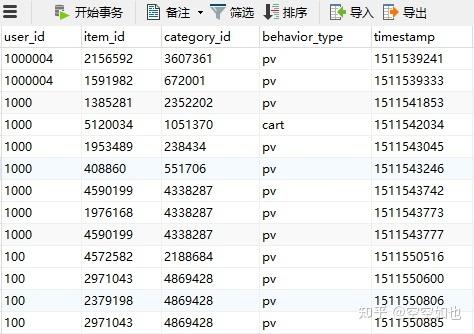
如何查找部分列重复的记录?
有时候我们只关心某些列的重复情况,比如只关注名字是否重复,而不关心其他列,这时可以使用DISTINCT关键字来简化查询。
3.1 查询特定列重复记录
SELECT name, COUNT(*) FROM employees GROUP BY name HAVING COUNT(*) > 1;
3.2 结果
| name | count |
| John | 2 |
删除重复记录
在找到重复记录后,有时我们需要删除这些重复项,这可以通过使用子查询来实现。
4.1 删除完全重复的记录
DELETE FROM employees WHERE id NOT IN ( SELECT MIN(id) FROM employees GROUP BY name, age, department );
4.2 删除部分列重复的记录(例如只保留年龄最小的记录)
DELETE FROM employees WHERE id NOT IN ( SELECT MIN(id) FROM employees GROUP BY name, age );
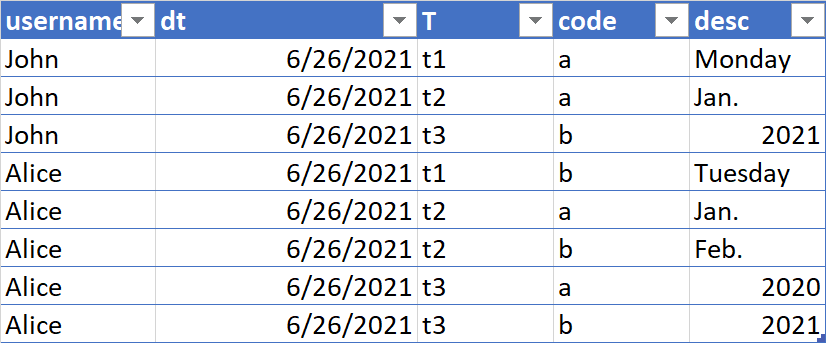
常见问题与解答
问题1: 如果表中有多个字段组合起来才能确定唯一性,如何查找这些组合的重复记录?
解答: 在这种情况下,可以将这些字段一起放在GROUP BY子句中,然后使用HAVING子句来过滤出重复的组合,如果需要查找name和age组合重复的记录,可以使用以下查询:
SELECT name, age, COUNT(*) FROM employees GROUP BY name, age HAVING COUNT(*) > 1;
问题2: 如何仅保留每组中的一条记录?
解答: 可以使用子查询和聚合函数来标识每组中的最小ID或其他唯一标识符,然后删除那些不在该子查询结果集中的记录,仅保留每个name和age组合中id最小的记录:
DELETE FROM employees WHERE id NOT IN ( SELECT MIN(id) FROM employees GROUP BY name, age );
通过以上方法,我们可以有效地查找和处理SQL表中的重复记录,无论是完全重复还是部分列重复,希望这些内容能帮助你在实际工作中更好地管理数据重复问题。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/53718.html