
您提供的内容不足以生成摘要。请提供具体的信息或文本,以便我能够更好地帮助您。如果您需要查询重复的记录,请告诉我您希望在哪个领域或上下文中进行查询(数据库、文件、网页等),以及您希望如何定义和处理重复项。这样,我就可以为您提供更具体和有用的建议。
在数据库管理和数据分析中,经常需要识别和处理重复的记录,重复记录可能由于数据输入错误、系统错误或多次导入相同数据集等原因产生,正确识别和管理这些重复记录对于保持数据的准确性和完整性至关重要,本文将详细介绍如何查询和处理重复的记录,并提供一些常见问题的解答。
什么是重复记录?
重复记录指的是在数据库中存在的两条或多条内容完全相同的记录,这些记录可能在所有的字段上都是相同的,也可能只是在关键字段(如主键)上相同。
如何识别重复记录?
1. 定义重复标准
需要明确什么样的记录被认为是重复的,是否所有字段都必须相同,还是只需关键字段相同即可。
2. 使用SQL查询
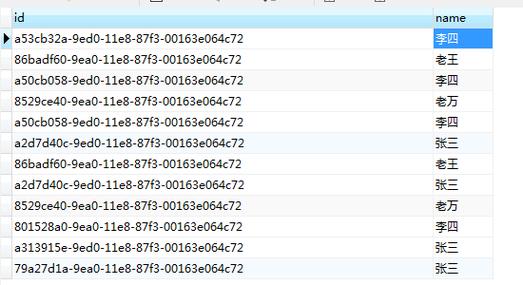
在关系型数据库中,可以使用SQL查询来查找重复记录,以下是一个基本的查询示例,用于查找表中所有字段都相同的重复记录:
SELECT column1, column2, ..., columnN, COUNT(*) FROM table_name GROUP BY column1, column2, ..., columnN HAVING COUNT(*) > 1;
如果只需要基于某些关键字段来查找重复记录,可以修改GROUP BY子句中的字段列表。
3. 使用数据管理软件
在一些高级的数据管理软件中,如Excel、Tableau等,通常提供了内置的工具来帮助识别和标记重复记录。
如何处理重复记录?
一旦识别出重复记录,下一步是决定如何处理它们,常见的处理方法包括:

删除:从数据库中完全删除重复的记录。
合并:将重复记录的关键信息合并到一条记录中,然后删除其他重复项。
标记:为重复记录添加一个标记,以便后续分析或审核。
选择哪种方法取决于具体的业务需求和数据策略。
相关问题与解答
Q1: 如果数据库非常大,如何高效地查找重复记录?
A1: 对于大型数据库,直接使用SQL查询可能会导致性能问题,在这种情况下,可以考虑以下策略:
使用索引:确保关键列上有适当的索引,这可以显著提高查询速度。
分批处理:将数据分成较小的批次进行处理,而不是一次性处理整个表。
使用临时表:创建临时表来存储中间结果,减少对原始表的影响。
Q2: 在处理重复记录时,如何避免误删重要数据?
A2: 在删除任何数据之前,应该采取以下预防措施:
备份数据:始终在操作前备份数据,以防万一出现错误可以恢复。
验证结果:在执行最终删除或更新操作之前,仔细检查查询结果以确保正确性。
逐步进行:先对一小部分数据进行操作,确认无误后再扩展到整个数据集。
通过遵循这些最佳实践,可以最大限度地减少处理重复记录时的风险。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/53738.html
