
在数据库管理和数据分析中,查询重复数据是常见需求。通过SQL查询语句可高效定位和处理表中的重复记录。本文将详细介绍如何查询重复数据的步骤及示例。
选择要检查的表
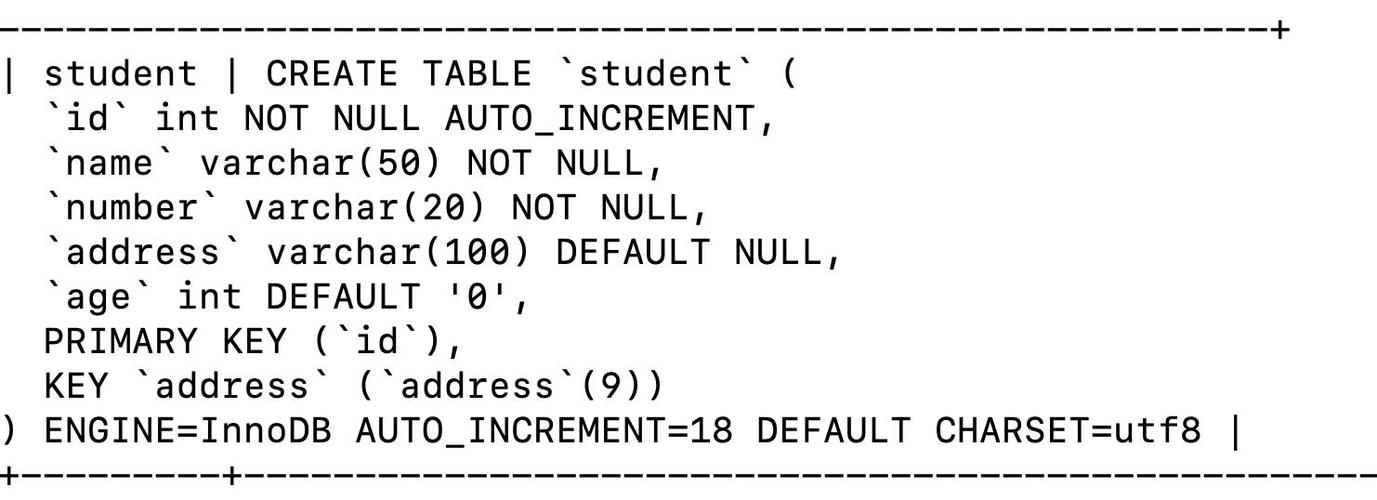
需要确定要检查哪个表,假设有一个名为Employees的表,其结构如下:

| Column | Type |
| id | INT |
| name | VARCHAR(50) |
| VARCHAR(100) | |
| department | VARCHAR(50) |
编写SQL查询找到重复记录
1. 基本查询
使用GROUP BY子句结合HAVING条件来查找某列字段相同的重复数据,要查找email字段中的重复记录,可以使用以下查询:
SELECT email, COUNT(*) as count FROM Employees GROUP BY email HAVING COUNT(*) > 1;
这个查询将返回所有email字段重复的记录及其重复次数。
2. 获取完整的重复记录
如果需要获取这些重复记录的详细信息,可以将上述查询作为子查询,与原表进行连接:
SELECT e.*
FROM Employees e
JOIN (
SELECT email, COUNT(*) as count
FROM Employees
GROUP BY email
HAVING COUNT(*) > 1
) dup ON e.email = dup.email;
这个查询将返回所有email字段重复的完整记录。
示例与扩展
1. 多列重复数据查询
有时可能需要查询多列组合的重复数据,要查找name和department组合重复的记录,可以使用以下查询:
SELECT name, department, COUNT(*) as count FROM Employees GROUP BY name, department HAVING COUNT(*) > 1;
2. 特定条件下的重复数据查询
如果需要在特定条件下查询重复数据,可以在查询中添加WHERE子句,要查找在特定部门(如"Sales")中email字段重复的记录:
SELECT email, COUNT(*) as count FROM Employees WHERE department = 'Sales' GROUP BY email HAVING COUNT(*) > 1;
常见问题与解答
1.如何在MySQL中删除重复数据?
在MySQL中,可以使用DELETE语句结合子查询来删除重复数据,要删除Employees表中email字段重复的记录,保留每个重复组中的一个记录,可以使用以下查询:
DELETE e1 FROM Employees e1 INNER JOIN Employees e2 WHERE e1.id > e2.id AND e1.email = e2.email;
2.如何处理包含NULL值的重复数据?
在处理包含NULL值的重复数据时,需要注意NULL值在比较时的特殊性,可以使用IS NOT DISTINCT FROM操作符来处理NULL值,要查找name字段中包含NULL值的重复记录,可以使用以下查询:
SELECT name, COUNT(*) as count FROM Employees GROUP BY name HAVING COUNT(*) > 1 OR name IS NOT DISTINCT FROM NULL;
通过以上步骤和示例,可以有效地查询和处理数据库中的重复数据,根据具体需求,可以灵活调整查询语句以适应不同情况。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/54562.html