
分页查询技术是一种在数据库中高效检索大量数据的方法,通过将数据分成多个小部分(页)来提高查询性能和用户体验。它通常涉及指定查询的起始位置和返回记录的数量,支持用户逐步浏览数据而无需一次性加载所有结果。
背景介绍
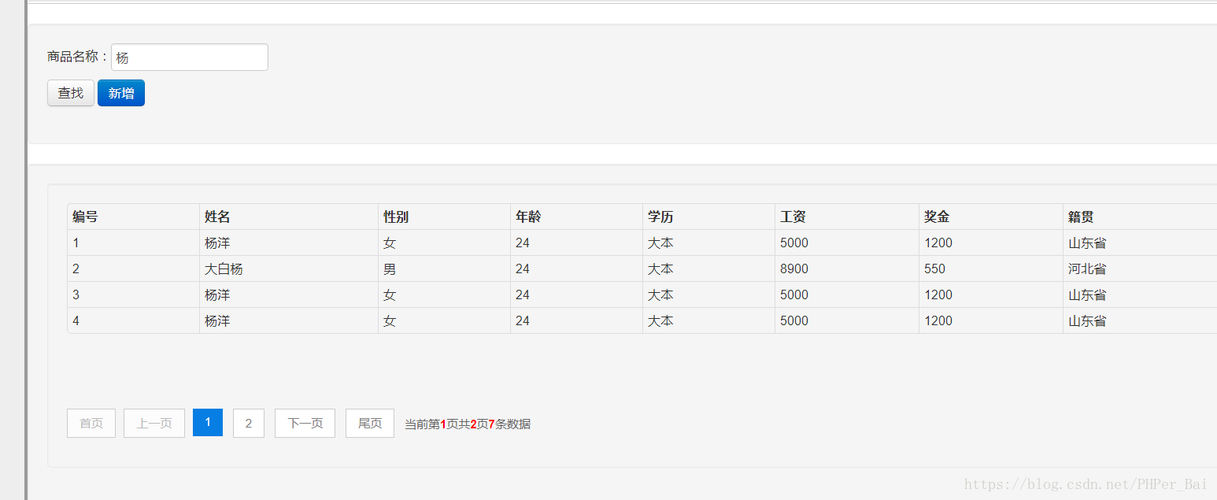

在处理大规模数据时,一次性加载所有数据到内存中是不现实的,分页查询成为了一种必要的手段,以减少服务器的压力,提高响应速度,分页查询允许用户按页浏览数据,而不是一次加载所有数据。
Java中的List分页查询
基本概念
List: 一个有序的集合,可以存储任意类型的对象。
分页查询: 从大量的数据中提取出部分数据显示给用户。
实现步骤
1、创建List对象并添加元素
“`java
List<String> list = new ArrayList<>();
for (int i = 1; i <= 50; i++) {
list.add("Item " + i);
}
“`
2、定义分页参数
“`java
int currentPage = 1; // 当前页码
int pageSize = 10; // 每页显示的记录数
“`
3、计算分页索引
“`java
int startIndex = (currentPage 1) * pageSize;
int endIndex = Math.min(startIndex + pageSize, list.size());
“`
4、执行分页操作
“`java
List<String> pageList = list.subList(startIndex, endIndex);
“`
5、输出结果
“`java
System.out.println("Current Page: " + currentPage);
System.out.println("Page List: " + pageList);
“`
完整代码示例
import java.util.ArrayList;
import java.util.List;
public class ListPagination {
public static void main(String[] args) {
// Step 1: Create a list and add elements
List<String> list = new ArrayList<>();
for (int i = 1; i <= 50; i++) {
list.add("Item " + i);
}
// Step 2: Define pagination parameters
int currentPage = 1; // Current page number
int pageSize = 10; // Number of records per page
// Step 3: Calculate pagination index
int startIndex = (currentPage 1) * pageSize;
int endIndex = Math.min(startIndex + pageSize, list.size());
// Step 4: Perform pagination operation
List<String> pageList = list.subList(startIndex, endIndex);
// Step 5: Output the result
System.out.println("Current Page: " + currentPage);
System.out.println("Page List: " + pageList);
}
}
MyBatisPlus中的分页查询
使用MyBatisPlus进行分页查询
1、引入依赖
“`xml
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatisplusbootstarter</artifactId>
<version>3.4.1</version>
</dependency>
“`
2、配置分页插件
“`yaml
mybatisplus:
configuration:
pagehelper: true
“`
3、编写Mapper接口
“`java
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
“`
4、执行分页查询
“`java
Page<User> page = new Page<>(currentPage, pageSize);
IPage<User> userPage = userMapper.selectPage(page, null);
List<User> userList = userPage.getRecords(); // Current page records
long total = userPage.getTotal(); // Total records
“`
完整代码示例
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public PageInfo<User> getUserPage(int currentPage, int pageSize) {
Page<User> page = new Page<>(currentPage, pageSize);
IPage<User> userPage = userMapper.selectPage(page, new QueryWrapper<>());
return new PageInfo<>(userPage);
}
}
Redis List实现分页查询
背景介绍
Redis List是一种链表数据结构,适合用于高效地存储和访问大量数据,通过结合Sorted Set和List,可以实现高效的分页查询。
实现步骤
1、数据存储:将数据存储在Redis List中,并在Sorted Set中存储记录的索引。
“`bash
LPUSH data_list "record1"
ZADD index_set 1 "record1"
“`
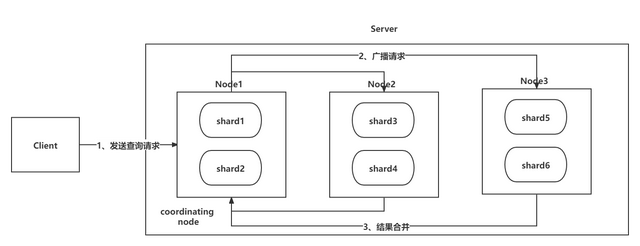
2、分页查询:根据用户请求的页码和每页数量,计算出在Sorted Set中的索引范围,然后通过List命令获取相应的记录。
“`bash
ZRANGEBYSCORE index_set start_index end_index
LRANGE data_list start end
“`
注意事项
数据同步:当数据库中的数据发生变化时,需要及时同步更新Redis中的List和Sorted Set。
性能考虑:根据实际情况调整List和Sorted Set的存储结构,以获得更好的性能。
完整代码示例
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Tuple;
import java.util.List;
import java.util.Set;
public class RedisPagination {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost");
String key = "data_list";
String indexKey = "index_set";
int currentPage = 1;
int pageSize = 10;
int totalCount = Integer.parseInt(jedis.zcard(indexKey).toString());
int totalPage = (totalCount + pageSize 1) / pageSize;
int startIndex = (currentPage 1) * pageSize + 1;
int endIndex = Math.min(startIndex + pageSize 1, totalCount);
Set<Tuple> indexRange = jedis.zrangeByScoreWithScores(indexKey, startIndex, endIndex);
List<String> ids = new ArrayList<>();
for (Tuple tuple : indexRange) {
ids.add(tuple.getElement());
}
List<String> pageData = jedis.lrange(key, startIndex 1, endIndex 1);
System.out.println("Current Page: " + currentPage);
System.out.println("Page Data: " + pageData);
}
}
相关问题与解答的栏目:
问题1:如何在Java中使用List的subList方法进行分页查询?
答:在Java中,可以使用List的subList方法进行分页查询,创建一个List对象并添加元素,然后定义分页参数(当前页码和每页显示的记录数),计算分页索引(起始索引和结束索引),最后使用subList方法获取指定范围内的元素,以下是一个示例代码:
import java.util.ArrayList;
import java.util.List;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.Map;
import java.util.HashMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.HashMap;
import java.util.*; import org.apache.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org.*; import com.*; import org; bsp; s;                                                                                                                      &thinSp ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ;&txt{9F99D3F687C64E5AA76B580AD79B5FA2}&text{9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687C6,4E5AA76B580AD79B5Ftext{9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687C64E5AA76B5000A79F687C64E5AA76B5807AD79B5Ftext{9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687C64E5AA76B5000A79B5Ftext{9F99D3F687C64E5AA76B580AD79B5Ftext=text{9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687CText{9F99D3F687C64E5AA76B580AD79B5Ftext{9F9S9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687C64F687C64E5A580AD79B5Ftext{9F99D687C64E5A580AD79B5Ftext{9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687C64E5A57C64E5A580AD79B5Ftext{0000A79B5Ftext{9F99D3F687C64E5AA76B580AD79B5Ftext{9F99D3F687C64E5A580AD79B5Ftext{9F99D3F687C64E5A580AD79B5Ftext=text{9F99D3F687C64E5A580AD79B5Ftext{9F99D3F687C64E5A580AD79B5Ftext{9F99D3F687C64E5A580AD79B5Ftext{9F99D3F687C64E5A5000A79B5Ftext{9F99D3F687C64E5A580AD79B5Ftext{9_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, totoIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_sub Set(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)_list_subList(fromIndex, toIndex)
表格:Java List分页查询示例代码及说明
| 序号 | 代码段 | 说明 |
||||
| 1 |List<String> list = new ArrayList<>(); | 创建一个ArrayList实例。 |
| 2 |for (int i = 1; i <= 50; i++) { list.add("Item " + i); } | 向List中添加元素。 |
| 3 |int currentPage = 1; int pageSize = 10; | 定义当前页码和每页显示的记录数。 |
| 4 |int startIndex = (currentPage 1) * pageSize; | 计算起始索引。 |
| 5 |int endIndex = Math.min(startIndex + pageSize, list.size()); | 计算结束索引。 |
| 6 |List<String> pageList = list.subList(startIndex, endIndex); | 使用subList方法获取分页后的数据。 |
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/56800.html