
数据库分表查询是一种优化大数据量处理的方法,通过将数据分布在多个表中,以提高查询性能和数据管理效率。它适用于高并发访问和大规模数据场景。
在处理大量数据时,单表的性能可能会下降,为了提高性能和可扩展性,通常会将一个表的数据分散到多个表中,这个过程称为分表(Sharding),分表可以是水平的(按行)或垂直的(按列),也可以是两者的结合,本文主要讨论水平分表及其查询策略。
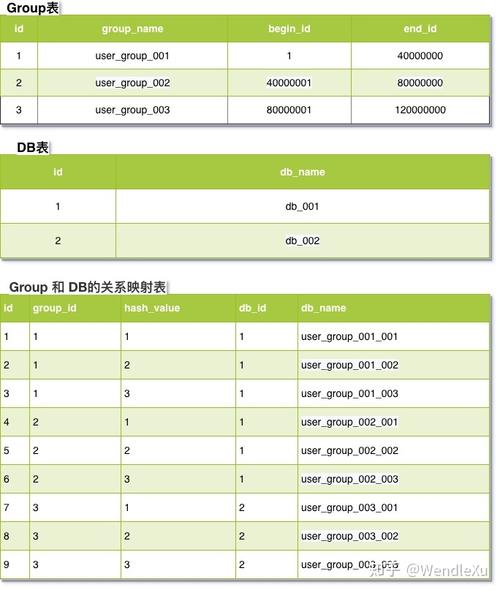

水平分表
水平分表是指将一个表的数据按行进行分割,分散到多个具有相同结构的表中,通常根据某个关键字段(如用户ID、订单号等)进行分表,假设有一个用户表users,可以根据用户ID的范围将其分到不同的表中。
分表规则
表名:user_<id_range>,其中<id_range> 是用户ID的范围。
例子:user_0,user_1,user_2, …,user_9。
示例
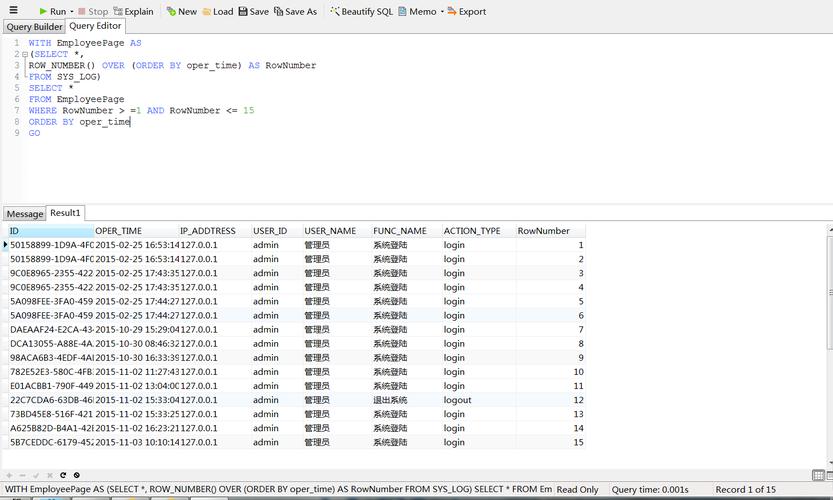
假设我们有以下用户表结构:
| id | name | age | |
| 1 | Alice | alice@example.com | 30 |
| 2 | Bob | bob@example.com | 25 |
| 3 | Charlie | charlie@example.com | 22 |
按照用户ID的范围进行分表后,表结构可能如下:
user_0:
| id | name | age | |
| 1 | Alice | alice@example.com | 30 |
user_1:
| id | name | age | |
| 2 | Bob | bob@example.com | 25 |
user_2:
| id | name | age | |
| 3 | Charlie | charlie@example.com | 22 |
分表查询策略
在分表之后,查询操作需要根据分表规则来确定从哪个表中获取数据,以下是一些常见的查询策略:
直接查询
如果已知用户ID,可以直接构建SQL语句查询对应的表,查询ID为1的用户信息:
SELECT * FROM user_0 WHERE id = 1;
动态SQL
对于未知用户ID的情况,可以通过编程语言动态生成SQL语句,在Java中:
String tableName = "user_" + userId % 10; // 根据分表规则确定表名 String sql = "SELECT * FROM " + tableName + " WHERE id = " + userId; // 执行SQL查询并处理结果
联合查询
如果需要跨多个表查询,可以使用UNION ALL操作符,查询所有用户信息:
(SELECT * FROM user_0) UNION ALL (SELECT * FROM user_1) UNION ALL (SELECT * FROM user_2);
注意:这种方法在表数量较多时可能会导致性能问题。
相关问题与解答
问题1: 如果需要对分表后的数据进行复杂的多表关联查询,如何处理?
答案: 对于复杂的多表关联查询,可以考虑以下方法:
1、汇总表:创建汇总表,定期将各分表的数据合并到一个表中,然后在这个汇总表上进行查询,但需要注意汇总表的数据同步和更新问题。
2、分布式事务:使用分布式事务来保证跨表操作的一致性,但这会增加系统的复杂性和开销。
3、NoSQL数据库:考虑使用NoSQL数据库,它们通常具有更好的水平扩展能力,可以处理大规模数据的复杂查询。
问题2: 如何选择合适的分表策略?
答案: 选择合适的分表策略需要考虑以下因素:
1、数据量:根据数据量的大小选择适当的分表粒度,如果数据量很大,可以选择更细粒度的分表;反之,则可以选择较粗粒度的分表。
2、查询模式:分析查询模式,如果大部分查询都是针对特定范围的数据,可以选择基于范围的分表策略,如果查询涉及多个范围,可以考虑其他策略。
3、维护成本:分表会增加系统的复杂性和维护成本,需要权衡分表带来的好处和维护成本之间的关系。
4、扩展性:确保所选的分表策略具有良好的扩展性,以便在未来可以轻松地添加更多的表或调整分表规则。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/57434.html