
SQL(Structured Query Language)是一种用于管理关系数据库的标准编程语言,它允许用户从数据库中检索、插入、更新和删除数据,以下是一些常见的SQL查询语句示例,以及它们的解释和用法。

1. SELECT语句
SELECT语句用于从数据库表中选择数据,它可以返回一个或多个列的数据,也可以使用条件过滤结果。
示例1:选择所有列
SELECT * FROM table_name;
这将返回表中的所有行和列。
示例2:选择特定列
SELECT column1, column2 FROM table_name;
这将仅返回指定的列。
示例3:选择满足条件的行
SELECT * FROM table_name WHERE condition;
这将返回满足指定条件的行。
2. INSERT语句
INSERT语句用于向数据库表中插入新的记录。
示例1:插入单条记录
INSERT INTO table_name (column1, column2) VALUES (value1, value2);
这将在表中插入一条新记录,其中column1的值为value1,column2的值为value2。
示例2:插入多条记录
INSERT INTO table_name (column1, column2) VALUES (value1, value2), (value3, value4);
这将在表中插入两条新记录。
3. UPDATE语句
UPDATE语句用于修改数据库表中的现有记录。
示例1:更新单个字段
UPDATE table_name SET column1 = value1 WHERE condition;
这将更新满足条件的记录中的column1字段为value1。
示例2:更新多个字段
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;
这将更新满足条件的记录中的column1和column2字段。
4. DELETE语句
DELETE语句用于从数据库表中删除记录。
示例1:删除满足条件的记录
DELETE FROM table_name WHERE condition;
这将删除满足指定条件的记录。
示例2:删除所有记录
DELETE FROM table_name;
这将删除表中的所有记录。
5. JOIN语句
JOIN语句用于将两个或多个表的行组合在一起,基于这些表之间的相关列。
示例1:内连接(INNER JOIN)
SELECT column1, column2 FROM table1 INNER JOIN table2 ON table1.common_column = table2.common_column;
这将返回两个表中具有相同common_column值的行。
示例2:左连接(LEFT JOIN)
SELECT column1, column2 FROM table1 LEFT JOIN table2 ON table1.common_column = table2.common_column;
这将返回table1中的所有行,以及与table2中匹配的行,如果没有匹配项,则table2的列将为NULL。
示例3:右连接(RIGHT JOIN)
SELECT column1, column2 FROM table1 RIGHT JOIN table2 ON table1.common_column = table2.common_column;
这将返回table2中的所有行,以及与table1中匹配的行,如果没有匹配项,则table1的列将为NULL。
6. GROUP BY语句
GROUP BY语句用于将结果集按照一个或多个列进行分组,通常与聚合函数(如COUNT、SUM、AVG等)一起使用。
示例1:按某列分组并计算总数
SELECT column1, COUNT(*) FROM table_name GROUP BY column1;
这将返回每个不同column1值的计数。
示例2:按多列分组并计算平均值
SELECT column1, column2, AVG(column3) FROM table_name GROUP BY column1, column2;
这将返回每个不同的column1和column2组合的column3平均值。
7. HAVING语句
HAVING语句用于过滤GROUP BY子句的结果集,它类似于WHERE语句,但适用于聚合函数。
示例1:筛选满足条件的分组结果
SELECT column1, COUNT(*) FROM table_name GROUP BY column1 HAVING COUNT(*) > 5;
这将返回column1的值及其计数大于5的分组。
示例2:筛选满足条件的分组结果并排序
SELECT column1, COUNT(*) FROM table_name GROUP BY column1 HAVING COUNT(*) > 5 ORDER BY COUNT(*) DESC;
这将返回按计数降序排列的column1的值及其计数大于5的分组。
问题与解答栏目
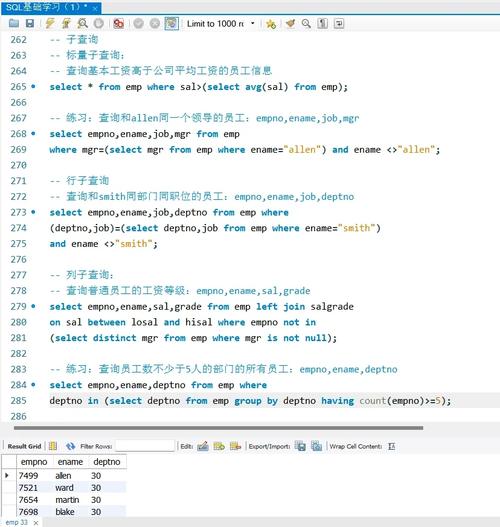
问题1:如何在SQL中使用子查询?
解答1:子查询是嵌套在其他SQL查询中的查询,你可以在SELECT、FROM、WHERE或HAVING子句中使用子查询,要从一个表中选择那些在另一个表中有匹配项的行,可以使用子查询:
SELECT column1 FROM table1 WHERE column2 IN (SELECT column2 FROM table2);
这将返回table1中column2值存在于table2中的column1值。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/6553.html